Preface
Hello there! I am an HTML and CSS expert that also hacks on server-side (PHP) and client-side (JavaScript) scripting languages. I am surprisingly productive at working with these elements even though I do not have a degree in Computer Science.
I like to use Sublime Text 2 – or whatever version – to work on my code. I want to work faster and Sublime Text’s multiple-cursor/multiple-file editing and fancy search tools are like training wheels for a person that never attempted to learn how to use Vi or Emacs.
With all of that out of the way, I’d like to say that REGULAR EXPRESSIONS ARE AWESOME. However, everyone online that tries to explain how to use them seems to think that they are talking to people that already know how to use them. It’s baffling and frustrating when you don’t have the foundation in text editing skills that everyone online assumes is common knowledge. And it’s not like you have to be a wizard to use regular expressions. If you can understand a few basic mechanisms, the rest is just vocabulary.
Find and Replace Basics
Find and Replace is a simple mechanism available in any serious text editor and also word processors and design layout applications.
Find and Replace at its most basic has two fields:
- FIND – A set and arrangement of text characters that you are specifically looking for within a defined range of text or a document.
- REPLACE – A set and arrangement of text characters with which you want to overwrite the contents of the FIND field.
In Sublime Text 2 there are four buttons associated with the Find and Replace panel:
- FIND – Visually highlight the first instance of text that matches the contents of the FIND field.
- FIND ALL – Visually highlight all instances of text that match the contents of the FIND field.
- REPLACE – Overwrite the first instance of text that matches the contents of the FIND field with the contents of the REPLACE field.
- REPLACE ALL – Overwrite all instances of text that match the contents of the FIND field with the contents of the REPLACE field.
In general, I only use REPLACE ALL since Sublime Text 2 pretty much does the FIND ALL functionality automatically as you type into the FIND field.
To bring up the Find and Replace panel, press CMD + Option + F or go the the menu > Find > Replace.
I’m not going to give an example of simple text find and replace. If you understand how CSS styles apply to specific HTML elements by way of element or class names and varying levels of inheritance, you most likely grok how basic find and replace works.
Employing Regular Expressions Within Find and Replace
What I am primarily interested in is leveraging Regular Expressions within the Find and Replace mechanism to achieve magical, time-saving actions.
Regular Expressions make it possible to automate what would otherwise be grueling manual-insertion tasks. For example, you need to convert tabulated data from a text file into tabulated data in an HTML table. Usually the only thing separating the values are varying numbers of spaces. Like this:
1 478 John Doe 48 M 6:20
2 472 Eddie Murphy 17 M 6:29
3 440 Indiana Jones 49 M 6:46
Basic Find and Replace would work fine in this scenario if a single, unique character were used to separate the different values – like the comma in a comma-delimited/comma-separated file. But when all you have is varying numbers of spaces, a more sophisticated tool like Regular Expressions is needed.
Actually, we could insert the table row and initial table data tags by leveraging the invisible line-break character in the data above. To get the necessary invisible characters use click-and-drag to select the line-break at the end of one line like this:

and Copy/Paste that into the FIND field. Then, in the REPLACE field type:
</td> </tr> <tr> <td>
and click REPLACE ALL to get the following:

But after that, we’re looking at a lot of manual select-and-paste work.
Let’s first use Regular Expressions to isolate the first and last name values. They are unique in this file in that the are two words separated by only one single space.
 Before we start employing Regular Expressions in the Find and Replace panel, we need to enable Regular Expressions by clicking a button by that name, which is the left-most top button in the Find and Replace panel:
Before we start employing Regular Expressions in the Find and Replace panel, we need to enable Regular Expressions by clicking a button by that name, which is the left-most top button in the Find and Replace panel:
With the Regular Expressions mode activated, this is what I put in the FIND field to isolate that space in that particular location:
([a-z]) ([A-Z])
Which should make Sublime Text 2 look like this:
So, that works in this instance! But why and how? Let’s break it down:
- [ ] Whatever expression is inside these brackets will match ONE character.
- [a-z] This expression means “ONE character that is any lowercase letter, a through z.”
- [A-Z] This expression means “ONE character that is any uppercase letter, A through Z.”
- The “space” in between these two expressions is a literal “space” character.
- ( ) Parenthesis surrounding an expression make a “group”. Groups can be referred to by variables. In this case we defined two groups. Without any effort on your part, these groups are numbered, starting with variable “1” on the left-most group and counting upward to the right. This will come in handy when we fill in the REPLACE field.
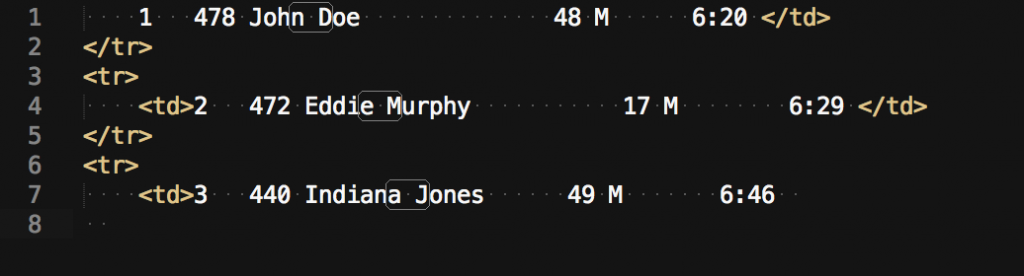
In summary: The FIND field includes regular expressions that identify any single lowercase letter followed by a space and then any single uppercase letter.
Now, in the REPLACE field I will type the following:
\1</td><td>\2
and after clicking REPLACE ALL will result in the following text:

That also worked! But why and how? Let’s break it down:
- \ is the “backslash” character, which “escapes” the character that follows it. I don’t completely understand this usage, but in the case of Sublime Text 2’s REPLACE field this means “leave whatever text that matched our regular expression in the group (identified by it’s variable number) where it was, do not replace”.
- In this example, we are telling Sublime Text 2 to leave the single lowercase letter associated with the variable “1” where it is, followed by the literal text “</td><td>” and then leave the single uppercase letter associated with the variable “2” where it is.
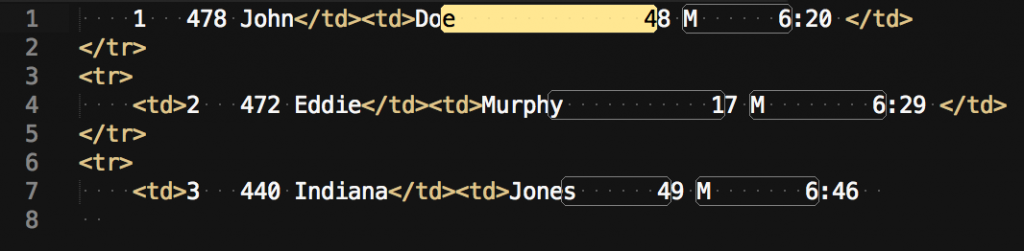
The next target is between the Last Name data and the number to the right of it. I will put the following text into the FIND field:
([a-z]) *([0-9])
This actually ends up working better than I had anticipated. It selects the desired text as well as another series of spaces between data points:
Since the first character is clearly supposed to be “lowercase only,” why is this second space between data points matching our search? Let’s break it down!
- [a-z] This expression means “ONE character that is any lowercase letter, a through z.”
- Turns out I had the “Case sensitive” feature (right next to the Regular Expressions button) disabled and as a result ignoring the case-sensitive aspects of my regular expressions! 🙂 Happy accident. Just something to be aware of if you are ever seeing confusing results.
- * A literal “space” followed by an asterisk. The asterisk directly following another character means “match 0 or more of the preceding character” so this is quite useful for selecting spaces between data points that are made up of varying numbers of spaces.
- ([0-9]) This expression means “ONE character that is any integer 0 through 9 (zero through nine).”
Since this lack of case-sensitivity actually worked for me, I went ahead with the same text in the REPLACE field as before and produced this result:

With those two examples I feel I’ve covered some very useful basics of Regular Expressions within the context of Sublime Text 2’s Find and Replace panel.
A good resource for learning more about regular expressions: http://www.zytrax.com/tech/web/regex.htm#simple
I tried to explain the basics of how to use Regular Expressions with Sublime Text 2’s Search and Replace panel. http://t.co/ikXF8ysKFS